

The best way to construct your individual AI bot to reply questions on your paperwork
An area AI to your personal paperwork will be actually helpful: Your personal chatbot reads all vital paperwork as soon as after which supplies the fitting solutions to questions equivalent to:
"What's the extra for my automobile insurance coverage?" or
"Does my supplementary dental insurance coverage additionally cowl inlays?"In case you are a fan of board video games, you possibly can hand over all the sport directions to the AI and ask the chatbot questions equivalent to:
"The place can I place tiles in Qwirkle?" We have now examined how nicely this works on typical house PCs.
See additionally: 4 free AI chatbots you possibly can run immediately in your PC
Necessities
To have the ability to question your individual paperwork with a totally native synthetic intelligence, you basically want three issues: a neighborhood AI mannequin, a database containing your paperwork, and a chatbot.
These three parts are offered by AI instruments equivalent to Something LLM and Msty. Each applications are freed from cost.
Set up the instruments on a PC with at the least 8GB of RAM and a CPU that’s as up-to-date as attainable. There needs to be 5GB or extra free house on the SSD.
Ideally, you must have a strong graphics card from Nvidia or AMD. This overview of suitable fashions may also help you.
By putting in Something LLM or Msty, you get a chatbot in your laptop. After set up, the instruments load an AI language mannequin, the Giant Language Mannequin (LLM), into this system.
Which AI mannequin runs within the chatbot will depend on the efficiency of your PC. Working the chatbot isn’t tough if you already know the fundamentals. Solely the in depth setting choices of the instruments require professional information.
However even with the usual settings, the chat instruments are straightforward to make use of. Along with the AI mannequin and the chatbot, Something LLM and Msty additionally provide the embedding mannequin, which reads in your doc and prepares it in a neighborhood database in order that the language mannequin can entry it.
Extra is best: Small AI fashions are hardly any good
There are AI language fashions that additionally run on weak {hardware}. For the native AI, weak means a PC with solely 8GB RAM and a CPU that’s already just a few years outdated and doesn’t have an excellent Nvidia or AMD graphics card.
AI fashions that also run on such PCs normally have 2 to three billion parameters (2B or 3B) and have been simplified by quantization.
This reduces reminiscence necessities and computing energy, but additionally worsens the outcomes. Examples of such variants are Gemma 2 2B or Llama 3.2 3B.
Though these language fashions are comparatively small, they supply surprisingly good solutions to numerous questions or generate usable texts based on your specs — utterly regionally and in an appropriate period of time.
If in case you have an excellent graphics card from Nvidia or AMD, you’re going to get a a lot sooner KIChatbot. This is applicable to the embedding course of and the ready time for a response. As well as, extra refined AI fashions can normally be used.
IDG
Nonetheless, on the subject of the native language mannequin taking your paperwork under consideration, these small fashions ship outcomes which might be someplace between “unusable” and “simply acceptable.” How good or dangerous the solutions are will depend on many elements, together with the kind of paperwork.
In our preliminary checks with native AI and native paperwork, the outcomes had been initially so poor that we suspected one thing had gone unsuitable with the embedding of the paperwork.
Additional studying: Past Copilot: 13 useful AI instruments for PC customers
Solely once we used a mannequin with 7 billion parameters did the responses enhance, and once we used the web mannequin ChatGPT 4o on a trial foundation, we had been capable of see how good the responses will be. So it wasn’t the embedding.
In actual fact, the largest lever for native AI and personal paperwork is the AI mannequin. And the larger it’s, i.e. the extra parameters it has, the higher. The opposite levers such because the embedding mannequin or the chatbot (Something LLM or Msty) and the vector database play a a lot, a lot smaller position.
Embedding & retrieval augmented era
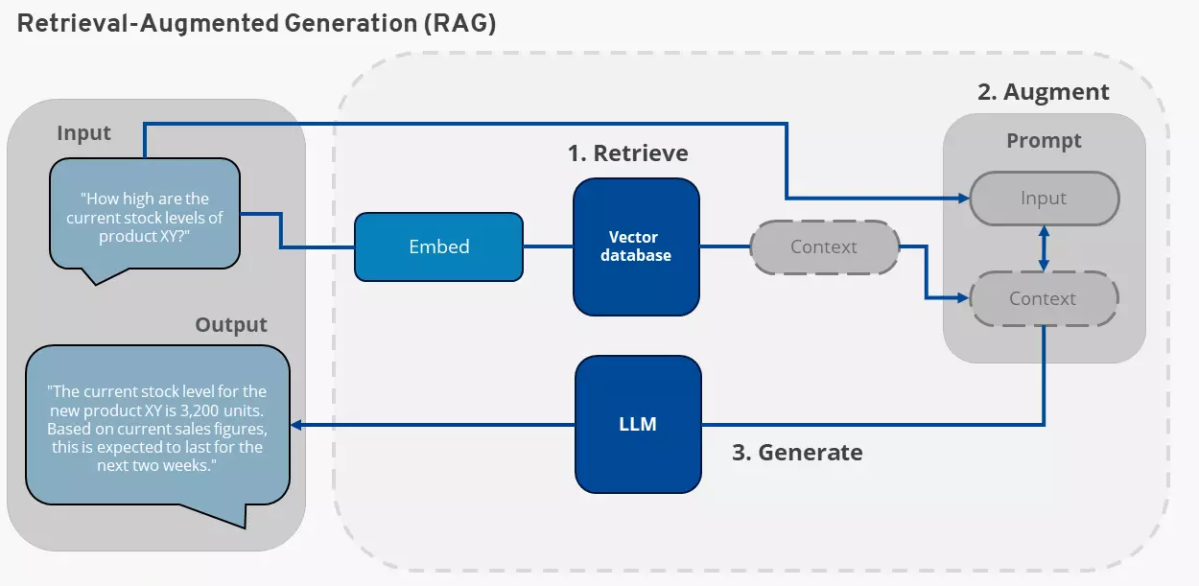
Cloud supplier Ionos explains how retrieval augmented era (RAG) works right here. That is the strategy by which an AI language mannequin takes your native doc under consideration in its responses. Ionos itself gives AI chatbots for its personal paperwork. Nonetheless, this normally runs completely within the cloud.
Ionos
Your personal knowledge is related to the AI utilizing a technique referred to as embedding and retrieval augmented era (RAG).
For instruments equivalent to Something LLM and Msty, it really works like this: Your native paperwork are analyzed utilizing an embedding mannequin. This mannequin breaks down the content material of the paperwork into its which means and shops it within the type of vectors.
As a substitute of a doc, the embedding mannequin may also course of data from a database or different information sources.
Nonetheless, the result’s all the time a vector database that comprises the essence of your paperwork or different sources. The type of the vector database allows the AI language mannequin to seek out objects in it.
This course of is basically totally different from a phrase search and a phrase index. The latter shops the place of an vital phrase in a doc. A vector database for RAG, then again, shops which statements are contained in a textual content.
This implies: The query:
"What's on web page 15 of my automobile insurance coverage doc?"doesn’t normally work with RAG. It’s because the data “web page 15” is normally not contained within the vector database. Most often, such a query causes the AI mannequin to hallucinate. Because it doesn’t know the reply, it invents one thing.
Creating the vector database, i.e. embedding your individual paperwork, is step one. The data retrieval is the second step and is known as RAG.
In retrieval augmented era, the person asks the chatbot a query. This query is transformed right into a vector illustration and in contrast with the info within the vector database of the person’s personal paperwork (retrieve).
The outcomes from the vector database at the moment are transferred to the chatbot’s AI mannequin along with the unique query (increase).
The AI mannequin now generates a solution (generate), which is made up of the data from the AI mannequin and the data from the person’s vector database.
Comparability: Something LLM or Msty?
We have now examined the 2 chatbots Something LLM and Msty. Each applications are related. Nonetheless, they differ considerably within the velocity with which they embed native paperwork, i.e. make them obtainable to the AI. This course of is mostly time-consuming.
Something LLM took 10 to fifteen minutes to embed a PDF file with round 150 pages within the take a look at. Msty, then again, typically took three to 4 occasions as lengthy.
We examined each instruments with their preset AI fashions for embedding. For Msty that is “Blended Bread Embed Giant,” for Something LLM it’s “All Mini LM L6 v2.”
Though Msty requires significantly extra time for embedding, it might be price selecting this instrument. It gives good person steerage and supplies actual supply data when citing. We suggest Msty for quick computer systems.
Additional studying: Does your subsequent laptop computer actually should be an AI PC?
For those who don’t have this, you must first attempt Something LLM and examine whether or not you possibly can obtain passable outcomes with this chatbot. The decisive issue is the AI language mannequin within the chatbot anyway. And each instruments provide the identical vary of AI language fashions.
By the way in which: Each Something LLM and Msty assist you to choose different embedding fashions. In some instances, nonetheless, the configuration turns into extra sophisticated. You may as well choose on-line embedding fashions, for instance from Open AI.
You don’t have to fret about by chance choosing a web-based embedding mannequin. It’s because you want an API key to have the ability to use it.
Something LLM: Easy and quick
Set up the Something LLM chatbot. Microsoft Defender Smartscreen might show a warning that the set up file isn’t safe. You may ignore this by clicking on “Run anyway.”
After set up, choose an AI language mannequin in Something LLM. We suggest Gemma 2 2B to start out with. You may substitute the chosen mannequin with a unique one at any time later (see “Change AI language mannequin” under).
Now create an space within the configuration wizard or later by clicking on “New workspace” in which you’ll import your individual paperwork. Give the workspace a reputation of your alternative after which click on on “Save.”
The brand new workspace now seems within the left bar of Something LLM. Click on on the icon to the left of the cogwheel image to import your doc for the AI. Within the new window, click on on “Click on to add or drag & drop” and choose your paperwork.
After just a few seconds, they’ll seem within the record above the button. Click on in your doc once more and choose “Transfer to Workspace,” which can transfer the paperwork to the fitting.
A closing click on on “Save and Embed” begins the embedding course of, which can take a while relying on the scale of the paperwork and the velocity of your PC.
Tip: Don’t attempt to learn the final 30 years of PCWorld as a PDF immediately. Begin with a easy textual content doc and see how lengthy it takes your PC. This fashion you possibly can shortly assess whether or not a extra in depth scan is worth it.
As soon as the method is full, shut the window and ask the chatbot your first query. To ensure that the chatbot to take your paperwork under consideration, you could choose the workspace you’ve got created on the left after which enter your query in the primary window on the backside beneath “Ship a message.”
Change the AI language mannequin: If you need to pick out a unique language mannequin in Something LLM, click on on the important thing image (“Open Settings”) on the backside left after which on “LLM.” Beneath “LLM supplier,” choose one of many urged AI fashions.
The brand new fashions from Deepseek are additionally supplied. Clicking on “Import mannequin from Ollama or Hugging Face” provides you entry to virtually all present, free AI fashions.
Downloading one of many fashions can take a while, as they’re a number of GB in dimension and the obtain server doesn’t all the time ship shortly. If you need to make use of a web-based AI mannequin, choose it from the drop-down menu under “LLM supplier.”
Suggestions for utilizing Something: Some Something LLM menus are a bit difficult. Adjustments to the settings normally should be confirmed by clicking on “Save.”
Nonetheless, the button for this shortly disappears from view on longer configuration pages. That is the case, for instance, when altering the AI fashions beneath “Open Settings > LLM.”
Anybody who forgets to click on the button will most likely be stunned that the settings are usually not utilized. It’s due to this fact vital to look out for a “Save” button each time you modify the configuration.
As well as, the person interface in Something LLM will be at the least partially switched to a different language beneath “Open settings > Customise > Show Language.”
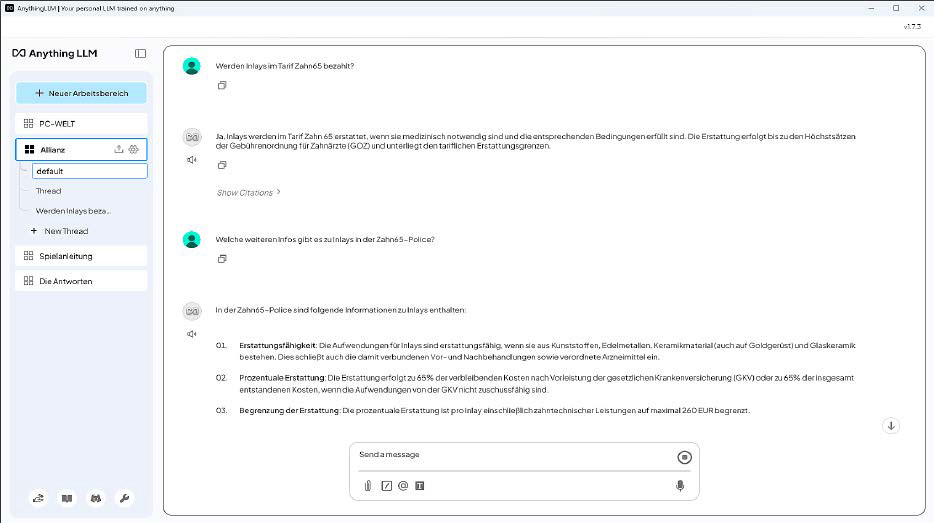
We additionally switched on the ChatGPT 4o on-line language mannequin as a take a look at, with excellent outcomes for questions on our supplementary dental insurance coverage contract and different paperwork.
IDG
Msty: Versatile chatbot for quick {hardware}
The Msty chatbot is considerably extra versatile than Something LLM by way of its attainable makes use of. It will also be used as a neighborhood AI chatbot with out integrating its personal recordsdata.
With Msty, a number of AI fashions will be loaded and used concurrently. Set up and configuration are just like Something LLM.
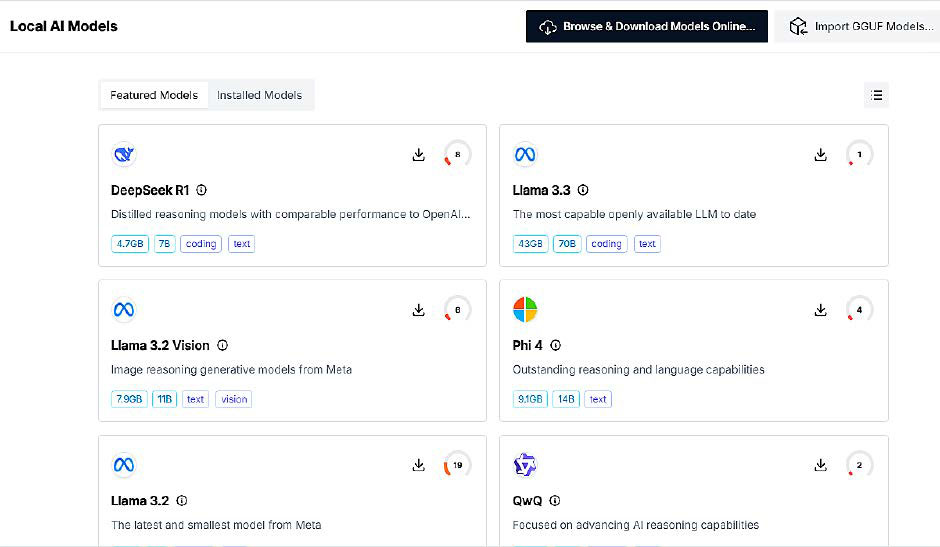
With the Msty chatbot, it’s straightforward to pick out a neighborhood AI language mannequin. The compatibility of every mannequin with the PC’s {hardware} can also be displayed. Values under 75 p.c are normally questionable.
IDG
What Something LLM calls “Workspace” is known as “Information Stack” in Msty and is configured beneath the menu merchandise of the identical identify on the backside left.
After getting created a brand new information stack and chosen your individual paperwork, you begin the embedding course of through “Compose.”
It might take a while for this to be accomplished. Again in the primary window of Msty, enter your query within the enter subject under.
To ensure that the chatbot to take your native paperwork under consideration, you could click on on the information stack image under the enter subject and place a tick in entrance of the specified information stack.
Fixing issues with incorrect or lacking solutions
If the solutions to your paperwork are usually not passable, we suggest that you just first choose a extra highly effective AI mannequin. For instance, if you happen to began with Gemma 2 2B with 2 billion parameters, attempt Gemma 2 9B. Or load Llama 3.1 with 8 billion parameters.
If this doesn’t convey ample enchancment or your PC takes too lengthy to reply, you possibly can contemplate switching to a web-based language mannequin. This may not see your native recordsdata or the vector database of your native recordsdata.
Nonetheless, it’s going to obtain the elements of your vector database which might be related to the given query. With Something LLM, you make the change individually for every workspace. To do that, click on on the cogwheel icon for a workspace and choose the supplier “Open AI” beneath “Chat settings > Workspace LLM supplier” to have the ability to use a mannequin from ChatGPT.
You’ll need to enter a paid API key from Open AI. This prices 12 {dollars}. The variety of responses you obtain will depend on the language mannequin used. Yow will discover an outline at openai.com/api/pricing.
If it isn’t attainable to modify to a web-based language mannequin for knowledge safety causes, the troubleshooting information from Something LLM may also help. On the one hand, it explains the essential prospects of embedding and RAG and, on the opposite, reveals the small configuration wheels that you would be able to flip to get higher solutions.
This text initially appeared on our sister publication PC-WELT and was translated and localized from German.


